This tutorial shows how to use the sparse approximate inverse (SPAI) preconditioner.
- Warning
- SPAI is currently only available with the OpenCL backend and is experimental. API-changes may happen any time in the future.
We start with including the necessary headers:
#define VIENNACL_WITH_UBLAS
#ifndef NDEBUG
#define BOOST_UBLAS_NDEBUG
#endif
#include <utility>
#include <iostream>
#include <fstream>
#include <string>
#include <cmath>
#include <algorithm>
#include <stdio.h>
#include "boost/numeric/ublas/vector.hpp"
#include "boost/numeric/ublas/matrix.hpp"
#include "boost/numeric/ublas/io.hpp"
The following helper routine is used to run a solver with the provided preconditioner and to print the resulting residual norm.
template<typename MatrixT, typename VectorT, typename SolverTagT, typename PreconditionerT>
void run_solver(MatrixT
const & A, VectorT
const & b, SolverTagT
const & solver_tag, PreconditionerT
const & precond)
{
std::cout << " * Solver iterations: " << solver_tag.iters() << std::endl;
residual -= b;
}
The main steps in this tutorial are the following:
- Setup the systems
- Run solvers without preconditioner and with ILUT preconditioner for comparison
- Run solver with SPAI preconditioner on CPU
- Run solver with SPAI preconditioner on GPU
- Run solver with factored SPAI preconditioner on CPU
- Run solver with factored SPAI preconditioner on GPU
int main (
int,
const char **)
{
typedef boost::numeric::ublas::compressed_matrix<ScalarType> MatrixType;
typedef boost::numeric::ublas::vector<ScalarType> VectorType;
If you have multiple OpenCL-capable devices in your system, we pick the second device for this tutorial.
#ifdef VIENNACL_WITH_OPENCL
std::vector<viennacl::ocl::device>
const & devices = pf.
devices();
if (devices.size() > 1)
else
#else
#endif
Create uBLAS-based sparse matrix and read system matrix from file
MatrixType M;
{
std::cerr<<"ERROR: Could not read matrix file " << std::endl;
exit(EXIT_FAILURE);
}
std::cout << "Size of matrix: " << M.size1() << std::endl;
std::cout << "Avg. Entries per row: " << double(M.nnz()) / static_cast<double>(M.size1()) << std::endl;
Use a constant load vector for simplicity
VectorType rhs(M.size2());
for (std::size_t i=0; i<rhs.size(); ++i)
Create the ViennaCL matrix and vector and initialize with uBLAS data:
GPUMatrixType gpu_M(M.size1(), M.size2(), ctx);
GPUVectorType gpu_rhs(M.size1(), ctx);
Solver Runs
We use a relative tolerance of 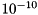 with a maximum of 50 iterations for each use case. Usually more than 50 solver iterations are required for convergence, but this choice ensures shorter execution times and suffices for this tutorial.
with a maximum of 50 iterations for each use case. Usually more than 50 solver iterations are required for convergence, but this choice ensures shorter execution times and suffices for this tutorial.
The first reference is to use no preconditioner (CPU and GPU):
std::cout << "--- Reference 1: Pure BiCGStab on CPU ---" << std::endl;
std::cout << " * Solver iterations: " << solver_tag.iters() << std::endl;
std::cout << "--- Reference 2: Pure BiCGStab on GPU ---" << std::endl;
std::cout << " * Solver iterations: " << solver_tag.iters() << std::endl;
gpu_residual -= gpu_rhs;
The second reference is a standard ILUT preconditioner (only CPU):
std::cout << "--- Reference 2: BiCGStab with ILUT on CPU ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
Step 1: SPAI with CPU
std::cout << "--- Test 1: CPU-based SPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
Step 2: FSPAI with CPU
std::cout << "--- Test 2: CPU-based FSPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
Step 3: SPAI with GPU
std::cout << "--- Test 3: GPU-based SPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
Step 4: FSPAI with GPU
std::cout << "--- Test 4: GPU-based FSPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
run_solver(gpu_M, gpu_rhs, solver_tag, fspai_gpu);
That's it! Print success message and exit.
std::cout << "!!!! TUTORIAL COMPLETED SUCCESSFULLY !!!!" << std::endl;
return EXIT_SUCCESS;
}
Full Example Code
#define VIENNACL_WITH_UBLAS
#ifndef NDEBUG
#define BOOST_UBLAS_NDEBUG
#endif
#include <utility>
#include <iostream>
#include <fstream>
#include <string>
#include <cmath>
#include <algorithm>
#include <stdio.h>
#include "boost/numeric/ublas/vector.hpp"
#include "boost/numeric/ublas/matrix.hpp"
#include "boost/numeric/ublas/io.hpp"
template<typename MatrixT, typename VectorT, typename SolverTagT, typename PreconditionerT>
void run_solver(MatrixT
const & A, VectorT
const & b, SolverTagT
const & solver_tag, PreconditionerT
const & precond)
{
std::cout << " * Solver iterations: " << solver_tag.iters() << std::endl;
residual -= b;
}
int main (
int,
const char **)
{
typedef boost::numeric::ublas::compressed_matrix<ScalarType> MatrixType;
typedef boost::numeric::ublas::vector<ScalarType> VectorType;
#ifdef VIENNACL_WITH_OPENCL
std::vector<viennacl::ocl::device>
const & devices = pf.
devices();
if (devices.size() > 1)
else
#else
#endif
MatrixType M;
{
std::cerr<<"ERROR: Could not read matrix file " << std::endl;
exit(EXIT_FAILURE);
}
std::cout << "Size of matrix: " << M.size1() << std::endl;
std::cout << "Avg. Entries per row: " << double(M.nnz()) / static_cast<double>(M.size1()) << std::endl;
VectorType rhs(M.size2());
for (std::size_t i=0; i<rhs.size(); ++i)
GPUMatrixType gpu_M(M.size1(), M.size2(), ctx);
GPUVectorType gpu_rhs(M.size1(), ctx);
std::cout << "--- Reference 1: Pure BiCGStab on CPU ---" << std::endl;
std::cout << " * Solver iterations: " << solver_tag.iters() << std::endl;
std::cout << "--- Reference 2: Pure BiCGStab on GPU ---" << std::endl;
std::cout << " * Solver iterations: " << solver_tag.iters() << std::endl;
gpu_residual -= gpu_rhs;
std::cout << "--- Reference 2: BiCGStab with ILUT on CPU ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
std::cout << "--- Test 1: CPU-based SPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
std::cout << "--- Test 2: CPU-based FSPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
std::cout << "--- Test 3: GPU-based SPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
std::cout << "--- Test 4: GPU-based FSPAI ---" << std::endl;
std::cout << " * Preconditioner setup..." << std::endl;
std::cout << " * Iterative solver run..." << std::endl;
run_solver(gpu_M, gpu_rhs, solver_tag, fspai_gpu);
std::cout << "!!!! TUTORIAL COMPLETED SUCCESSFULLY !!!!" << std::endl;
return EXIT_SUCCESS;
}


 1.8.9.1
1.8.9.1